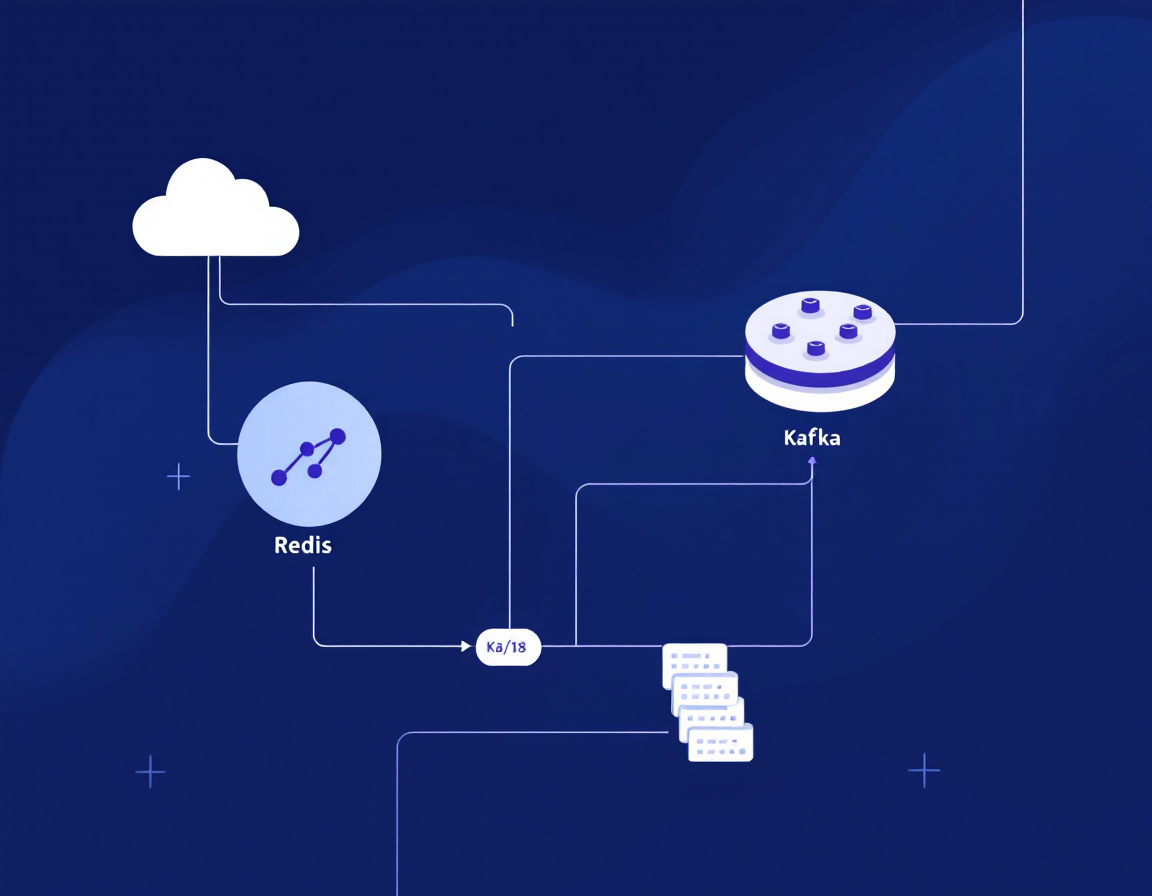
Storing and Managing Data with Redis and Apache Kafka on Heroku-18
Real-time data pipelines are non-negotiable in modern applications—and Redis plus Kafka is the stack powering them at scale. This course cuts through the theory and gets you hands-on with both technologies on Heroku-18, covering caching strategies, event streaming, and production-ready deployment patterns you’ll use immediately.
AIU.ac Verdict: Ideal for backend engineers and DevOps practitioners who need to architect high-throughput data systems without months of trial-and-error. The focused 1h 54m duration is a strength for busy professionals, though you’ll want foundational database knowledge beforehand to extract maximum value.
What This Course Covers
You’ll work through Redis fundamentals—data structures, persistence, and caching patterns—before moving into Apache Kafka’s publish-subscribe architecture and topic-based streaming. The course demonstrates real-world scenarios: session caching with Redis, event-driven workflows with Kafka, and integrating both on Heroku-18’s containerised platform.
Expect hands-on labs covering connection pooling, message serialisation, consumer groups, and monitoring. Saravanan Dhandapani walks you through deployment considerations specific to Heroku-18, including scaling strategies and cost optimisation. You’ll leave with working code patterns for common use cases: real-time analytics, order processing pipelines, and cache invalidation strategies.
Who Is This Course For?
Ideal for:
- Backend engineers building microservices: Need production patterns for caching and event streaming without deep distributed systems expertise.
- DevOps and platform engineers: Deploying data infrastructure on Heroku-18 and need to understand Redis/Kafka operational requirements.
- Full-stack developers scaling applications: Currently hitting performance walls and ready to implement proper caching and async processing layers.
May not suit:
- Complete beginners to databases: Assumes comfort with basic database concepts; you’ll struggle without prior SQL or NoSQL exposure.
- Enterprise architects designing multi-region systems: Heroku-18 focus and 1h 54m duration won’t cover distributed consensus, disaster recovery, or global replication strategies.
Frequently Asked Questions
How long does Storing and Managing Data with Redis and Apache Kafka on Heroku-18 take?
1 hour 54 minutes of video content. Plan 3–4 hours total including hands-on labs and experimentation.
Do I need prior Redis or Kafka experience?
No. The course assumes database fundamentals but teaches both Redis and Kafka from first principles. You should understand basic concepts like keys, values, and message queues.
Will this prepare me for production deployments?
Yes. Saravanan covers Heroku-18 deployment specifics, scaling, and operational patterns. You’ll have working code for real scenarios, though large-scale multi-region systems require additional study.
Is this course still relevant if I’m not using Heroku?
Absolutely. Redis and Kafka concepts are platform-agnostic. The Heroku-18 context is a practical deployment example; the patterns apply to AWS, GCP, Kubernetes, and on-premises infrastructure.
Course by Saravanan Dhandapani on Pluralsight. Duration: 1h 54m. Last verified by AIU.ac: March 2026.